简述
这篇文章学习源码中util/coding.h和util/coding.cc文件,这两个文件主要介绍了leveldb中使用的编码方式,包括变长和不变长两种。
leveldb默认采用小端字节序存储,即低位字节排放在内存的低地址中。
这篇文章不能简单靠注释了,其中有一些编码算法可以仔细看一下。
coding.h
先简单看下头文件,添加些注释。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98//
// Endian-neutral encoding(直译:尾数中和编码):
// 首先,固定长度的数字用最低有效位编码
// 其次,leveldb支持可变长度的varint编码
// 字符串以varint格式的长度作为前缀进行编码
namespace leveldb {
// 以下Put...方法将value加到string中。
void PutFixed32(std::string* dst, uint32_t value);
void PutFixed64(std::string* dst, uint64_t value);
void PutVarint32(std::string* dst, uint32_t value);
void PutVarint64(std::string* dst, uint64_t value);
void PutLengthPrefixedSlice(std::string* dst, const Slice& value);
// 以下Get...从一个Slice的开头开始解析一个值,并且将input移动到解析之后的位置
bool GetVarint32(Slice* input, uint32_t* value);
bool GetVarint64(Slice* input, uint64_t* value);
bool GetLengthPrefixedSlice(Slice* input, Slice* result);
// 基于指针的变种GetVarint...
// 它们要么在*v中存储一个值并返回一个刚刚经过解析的值的指针,要么在出现错误时返回nullptr。这些例程只查看范围[p..limit-1]内的字节。
const char* GetVarint32Ptr(const char* p, const char* limit, uint32_t* v);
const char* GetVarint64Ptr(const char* p, const char* limit, uint64_t* v);
// 返回v的varint32/varint64后的编码长度
int VarintLength(uint64_t v);
// 低级的put方法,会把value字节写入字符缓冲区
// 要求:dst有足够的空间给value写。
void EncodeFixed32(char* dst, uint32_t value);
void EncodeFixed64(char* dst, uint64_t value);
// 低级的put方法,会把value字节写入字符缓冲区并且返回一个指向最后写入字符之后位置的指针。
// 要求:dst有足够的空间给value写。
char* EncodeVarint32(char* dst, uint32_t value);
char* EncodeVarint64(char* dst, uint64_t value);
// 低级的get方法,直接从字符缓冲区中读取数据。没有任何边界检查。
inline uint32_t DecodeFixed32(const char* ptr) {
//小端存储
if (port::kLittleEndian) {
// 加载原始字节
uint32_t result;
memcpy(&result, ptr, sizeof(result)); // gcc将此优化成普通加载
return result;
} else {
return ((static_cast<uint32_t>(static_cast<unsigned char>(ptr[0]))) |
(static_cast<uint32_t>(static_cast<unsigned char>(ptr[1])) << 8) |
(static_cast<uint32_t>(static_cast<unsigned char>(ptr[2])) << 16) |
(static_cast<uint32_t>(static_cast<unsigned char>(ptr[3])) << 24));
}
}
// 同上,不过是64位的
inline uint64_t DecodeFixed64(const char* ptr) {
if (port::kLittleEndian) {
// Load the raw bytes
uint64_t result;
memcpy(&result, ptr, sizeof(result)); // gcc optimizes this to a plain load
return result;
} else {
uint64_t lo = DecodeFixed32(ptr);
uint64_t hi = DecodeFixed32(ptr + 4);
return (hi << 32) | lo;
}
}
// Internal routine for use by fallback path of GetVarint32Ptr
// 内部例程,用于GetVarint32Ptr方法的回退
const char* GetVarint32PtrFallback(const char* p, const char* limit,
uint32_t* value);
inline const char* GetVarint32Ptr(const char* p, const char* limit,
uint32_t* value) {
if (p < limit) {
uint32_t result = *(reinterpret_cast<const unsigned char*>(p));
if ((result & 128) == 0) {
*value = result;
return p + 1;
}
}
return GetVarint32PtrFallback(p, limit, value);
}
} // namespace leveldb
Fixint编码
Fixint是固定编码,比较简单,主要是根据小端还是大端存储来将字节放入缓冲区中,编码代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30//coding.cc
void EncodeFixed32(char* dst, uint32_t value) {
if (port::kLittleEndian) {
//如果是小端存储模式,则直接用memcpy将value拷贝到dst缓冲区中
memcpy(dst, &value, sizeof(value));
} else {
//如果不是小端存储模式,则利用位运算手动处理成小端模式存储到dst中
dst[0] = value & 0xff;
dst[1] = (value >> 8) & 0xff;
dst[2] = (value >> 16) & 0xff;
dst[3] = (value >> 24) & 0xff;
}
}
// 64位整数处理方式和32位大体相似,只不过64位要使用8个byte
void EncodeFixed64(char* dst, uint64_t value) {
if (port::kLittleEndian) {
memcpy(dst, &value, sizeof(value));
} else {
dst[0] = value & 0xff;
dst[1] = (value >> 8) & 0xff;
dst[2] = (value >> 16) & 0xff;
dst[3] = (value >> 24) & 0xff;
dst[4] = (value >> 32) & 0xff;
dst[5] = (value >> 40) & 0xff;
dst[6] = (value >> 48) & 0xff;
dst[7] = (value >> 56) & 0xff;
}
}
知道了编码方式,解码方式即是逆操作,解码实现代码在coding.h中,第一节已经里已经列出,可以看出同样是一开始先判断是否是小端存储,若是小端存储则直接用memcpy方法复制;如果不是小端存储,则利用位运算和或运算对每个byte进行整合得到最终结果。
值得注意的是,64位的解码方法DecodeFixed64没有像编码方法EncodeFixed64一样写完8个字节的处理,而是调用了两次DecodeFixed32方法分别处理了高4位和低4位,最后或了一下。
一般来说,能复用的代码都不会重复写,那为什么64位的编码方法EncodeFixed64没有选择复用EncodeFixed32而是自己写了8个byte的处理呢?
比如,写成下面这样:1
2
3
4
5
6
7
8void EncodeFixed64(char* dst, uint64_t value) {
if (port::kLittleEndian) {
memcpy(dst, &value, sizeof(value));
} else {
EncodeFixed32(dst, value);
EncodeFixed32(dst + 4, value >> 32);
}
}
我在vs2017上测了下好像和源码里提供的方法并没有什么区别,所以为什么源码里没有使用复用的方式呢?有点好奇,但问题不大,暂且忽略。【突然想到是不是大端机器上使用复用的方法会有点问题?但应该没有才对呀。。。】
Varint编码
Varint是一种紧凑的表示数字的方法,它用一个字节或多个字节来表示一个数字。它是一种使用一个或多个字节序列化整数的方法,会把整数编码为变长字节。对于32位整型数字而言,varint编码会将它编码成1~5个字节,小的数字只占用1个字节,大的则会占用5个字节,而根据统计学来说,小数字使用频率大于大数字,所以利用varint编码能够起到压缩空间的作用。
接下来详细看一下它的编解码过程。
另外说一句,最近发现varint编码方式应用似乎还是很广泛的,除了LevelDB外,项目中使用到的另一个开源工具Protobuf中也使用了这种编码,所以还是很有必要学习一下呀~
编码原理与实现
在varint编码中,除了最后一个字节外,其余每个字节都会设置一个最高有效位(most significant bit -msb),msb为1表示后面的字节还是属于当前数据的,为0则表示这是该数据的最后一个字节。所以每个字节的低7位为一组存储数字的二进制补码,最低有效组在前面,最高有效组在后面,即是小端存储。
根据上一段,我们可以算出Varint编码中为什么32位的整型最高需要5个字节来存储。本来每个32位整型需要4个byte来存储,现在改为Varint编码,每个byte只能表示7个bit,那么32个bit就需要32/7=5(向上取整)个byte来存储。
同理,64位整型使用Varint最多需要10个byte来存储(64/7=10[向上取整])。
编码原理如图所示:
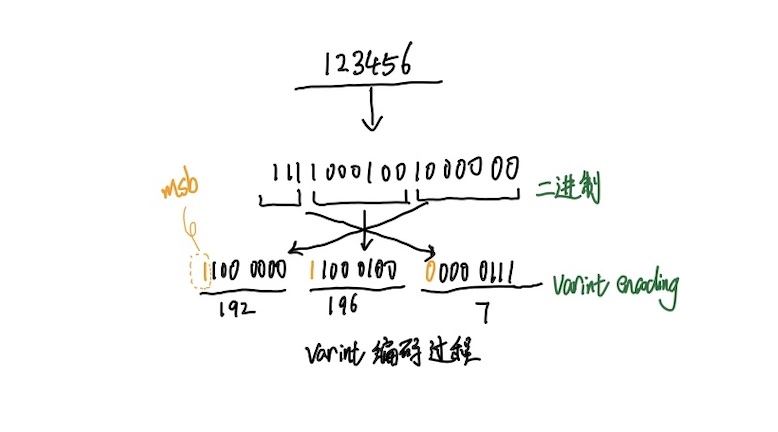
最终十进制123456经过Varint编码后的值变为1100 0000 1100 0100 0000 0111,所以123456占用的三个字节分别是192 196 7,图中一目了然(侵删)。
LevelDB源码Varint实现:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47char* EncodeVarint32(char* dst, uint32_t v) {
// Operate on characters as unsigneds
// 首先把字符当做无符号来处理,【这么做的原因是为了防止有符号数在进行移位时高位自动补充1从而导致数据错误??】
unsigned char* ptr = reinterpret_cast<unsigned char*>(dst);
static const int B = 128;
if (v < (1 << 7)) {
//v小于128,直接把v赋值给*ptr,因为v的有效位最多7位,
//v只需要一个byte即可表示,最高有效位是0
*(ptr++) = v;
} else if (v < (1 << 14)) {
//v需要两个byte表示
*(ptr++) = v | B;//和128进行或运算,使得第一个byte的最高有效位是1
*(ptr++) = v >> 7;//v先右移7位,然后处理第二个byte
} else if (v < (1 << 21)) {
//v需要三个byte表示,原理同上
*(ptr++) = v | B;
*(ptr++) = (v >> 7) | B;
*(ptr++) = v >> 14;
} else if (v < (1 << 28)) {
//v需要四个byte表示,原理同上
*(ptr++) = v | B;
*(ptr++) = (v >> 7) | B;
*(ptr++) = (v >> 14) | B;
*(ptr++) = v >> 21;
} else {
//v需要五个byte表示,原理同上
*(ptr++) = v | B;
*(ptr++) = (v >> 7) | B;
*(ptr++) = (v >> 14) | B;
*(ptr++) = (v >> 21) | B;
*(ptr++) = v >> 28;
}
return reinterpret_cast<char*>(ptr);
}
// 64位整型Varint编码实现,大体相同,只是这里的实现使用了循环,毕竟10个ifelse会很冗长,而且也没必要
// 要注意的是循环条件,退出循环后还需要处理最后的7位数据
char* EncodeVarint64(char* dst, uint64_t v) {
static const int B = 128;
unsigned char* ptr = reinterpret_cast<unsigned char*>(dst);
while (v >= B) {
*(ptr++) = v | B;
v >>= 7;
}
*(ptr++) = static_cast<unsigned char>(v);
return reinterpret_cast<char*>(ptr);
}
除了编码实现之外LevelDB还提供了一个返回编码后占用byte数的方法,即返回整型编码后的长度,同样是使用位运算实现的,代码如下:1
2
3
4
5
6
7
8int VarintLength(uint64_t v) {
int len = 1;
while (v >= 128) {
v >>= 7;
len++;
}
return len;
}
解码原理与实现
理解了编码原理,解码其实就是逆操作,可以直接看代码。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80//coding.cc
//从Slice获取value的方法,内部调用GetVarint32Ptr
bool GetVarint32(Slice* input, uint32_t* value) {
const char* p = input->data();
const char* limit = p + input->size();
const char* q = GetVarint32Ptr(p, limit, value);
if (q == nullptr) {
return false;
} else {
*input = Slice(q, limit - q);
return true;
}
}
//coding.h
//该方法处理value<128的情况,直接将result赋值给value,否则调用GetVarint32PtrFallback方法
inline const char* GetVarint32Ptr(const char* p, const char* limit,
uint32_t* value) {
if (p < limit) {
uint32_t result = *(reinterpret_cast<const unsigned char*>(p));
if ((result & 128) == 0) {
*value = result;
return p + 1;
}
}
return GetVarint32PtrFallback(p, limit, value);
}
//coding.cc
const char* GetVarint32PtrFallback(const char* p, const char* limit,
uint32_t* value) {
uint32_t result = 0;
// 每7位循环处理一次
for (uint32_t shift = 0; shift <= 28 && p < limit; shift += 7) {
uint32_t byte = *(reinterpret_cast<const unsigned char*>(p));
p++;
if (byte & 128) {
// 如果当前byte最高位为1,即说明当前数据后面还有byte
result |= ((byte & 127) << shift);
} else {
// 当前byte最高位为0,已经到了当前数据的最后一个byte
result |= (byte << shift);
*value = result;
return reinterpret_cast<const char*>(p);
}
}
return nullptr;
}
//64位整型处理和32位大同小异,只不过64位没有再分开成两个方法,统一处理了
//从slice解码64位整型数据,内部调用GetVarint64Ptr
bool GetVarint64(Slice* input, uint64_t* value) {
const char* p = input->data();
const char* limit = p + input->size();
const char* q = GetVarint64Ptr(p, limit, value);
if (q == nullptr) {
return false;
} else {
*input = Slice(q, limit - q);
return true;
}
}
//和32位处理几乎相同,只是循环条件稍微变了下
const char* GetVarint64Ptr(const char* p, const char* limit, uint64_t* value) {
uint64_t result = 0;
for (uint32_t shift = 0; shift <= 63 && p < limit; shift += 7) {
uint64_t byte = *(reinterpret_cast<const unsigned char*>(p));
p++;
if (byte & 128) {
// More bytes are present
result |= ((byte & 127) << shift);
} else {
result |= (byte << shift);
*value = result;
return reinterpret_cast<const char*>(p);
}
}
return nullptr;
}
其他
另外coding文件中还有几个其他的方法,主要是针对字符串的编解码方法,后续会使用到,这里简单看一下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29//该方法将Slice类的value的长度进行编码当做前缀放在dst中,后面跟value值
//即value编码后后变成这样的格式:[varint编码后的value长度值]+[value本身的data值]
void PutLengthPrefixedSlice(std::string* dst, const Slice& value) {
PutVarint32(dst, value.size());
dst->append(value.data(), value.size());
}
//该方法返回去掉长度前缀的整型值,存在result中
const char* GetLengthPrefixedSlice(const char* p, const char* limit,
Slice* result) {
uint32_t len;
p = GetVarint32Ptr(p, limit, &len);//p指向结果后一位的指针,即p越过了长度前缀
if (p == nullptr) return nullptr;
if (p + len > limit) return nullptr;
*result = Slice(p, len);//将p往后的len长度的真正值赋给result
return p + len;
}
//该方法去掉input的前缀,将data和size存到result中,input则变成
bool GetLengthPrefixedSlice(Slice* input, Slice* result) {
uint32_t len;
if (GetVarint32(input, &len) && input->size() >= len) {
*result = Slice(input->data(), len);
input->remove_prefix(len);
return true;
} else {
return false;
}
}
关于字符串的编解码,使用以下代码进行测试:1
2
3
4
5
6
7std::string s;
PutLengthPrefixedSlice(&s, Slice("alksdjf"));
cout << "s.data = " << s.data() << ", s.size = " << s.size() << endl;
Slice input(s);
Slice v;
GetLengthPrefixedSlice(&input, &v);
cout << "v.data = " << v.data() << ", v.size = " << v.size() << endl;
vs2017运行结果如下:1
2s.data = alksdjf, s.size = 8
v.data = alksdjf, v.size = 7
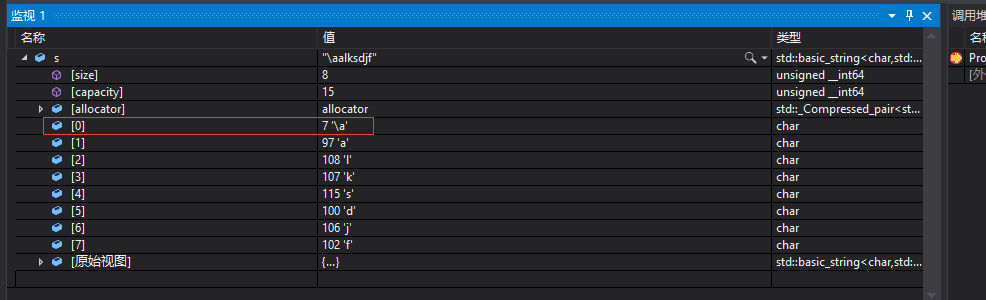
要注意的是s中在字符串开头还有一个隐藏字节,保存的是s的真正字符串长度7,只不过ASCII码表里7对应的字符\a无法打印出来的,debug调试是可以看到该值的,如图所示。
还有一点是测试中input指针的地址在GetLengthPrefixedSlice前后的变化如下1
2调用前:0x00000054296ffbd0
调用后:0x00000054296ffbd8
可以看出来正好向后移动了8位,和s.size相同。即在调用GetLengthPrefixedSlice之后,input会移动到原本数据的下一位,而数据的值会存在result中。
一通操作,还是很精妙的,建议将该测试代码自行debug一下,品,你细品。